When choosing a programming language or database, there are so many options to
choose from. And people regularly create new options since they are not happy
with the existing ones. But for version control, there exists essentially just
one option: Git. And while it takes some getting used to, it must do something
right, if nobody wants to spend the effort to improve upon it. This is a
small introduction.
The Basics
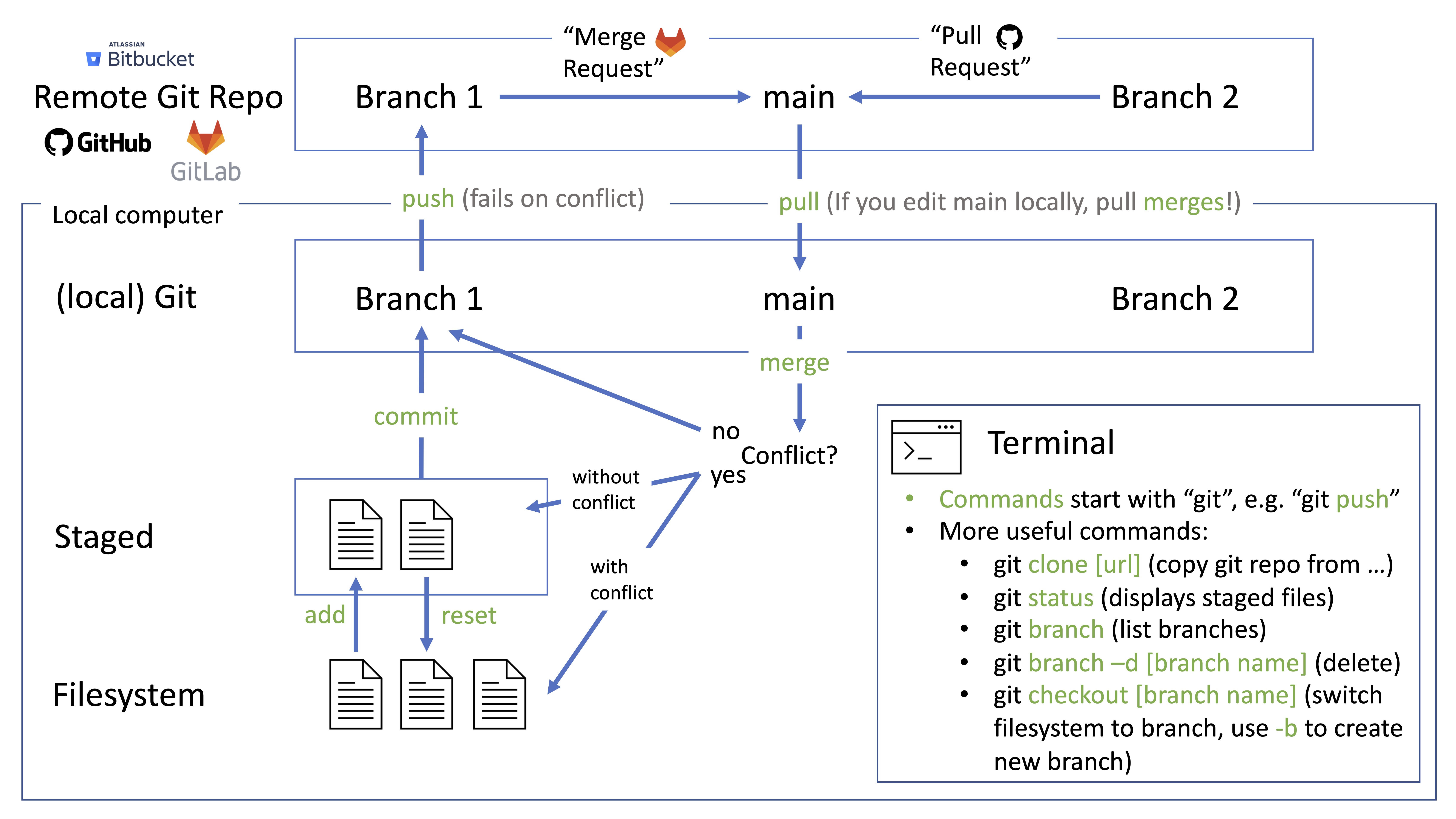
Git itself has a command-line interface. You initialize a git repository
with
$ git init
inside the folder you want to track changes in. By switching branches you can switch between different versions, git will update your filesystem accordingly.
While git itself is a local program, it is most powerful in conjunction with a
remote git repository. This repository on a server is nothing special, just
another git repository really.
Technically it is a little different. It is typically initialized with
git init --barewhich means it will not have a working tree (i.e. update the filesystem with the current branch) and thus does not allow you to work on it locally.
So Git is inherently decentral. You can push and
pull changes from any repository to another. So you might have multiple
remotes. But typically people use Git with one central remote server.
Services like GitHub provide such remote repositories. But additionally,
they also provide a Web UI to interact with these remote repositories. This
additional layer, provides features for collaboration (e.g. issues,
pull-requests) and things like automated testing (CI - continuous integration).
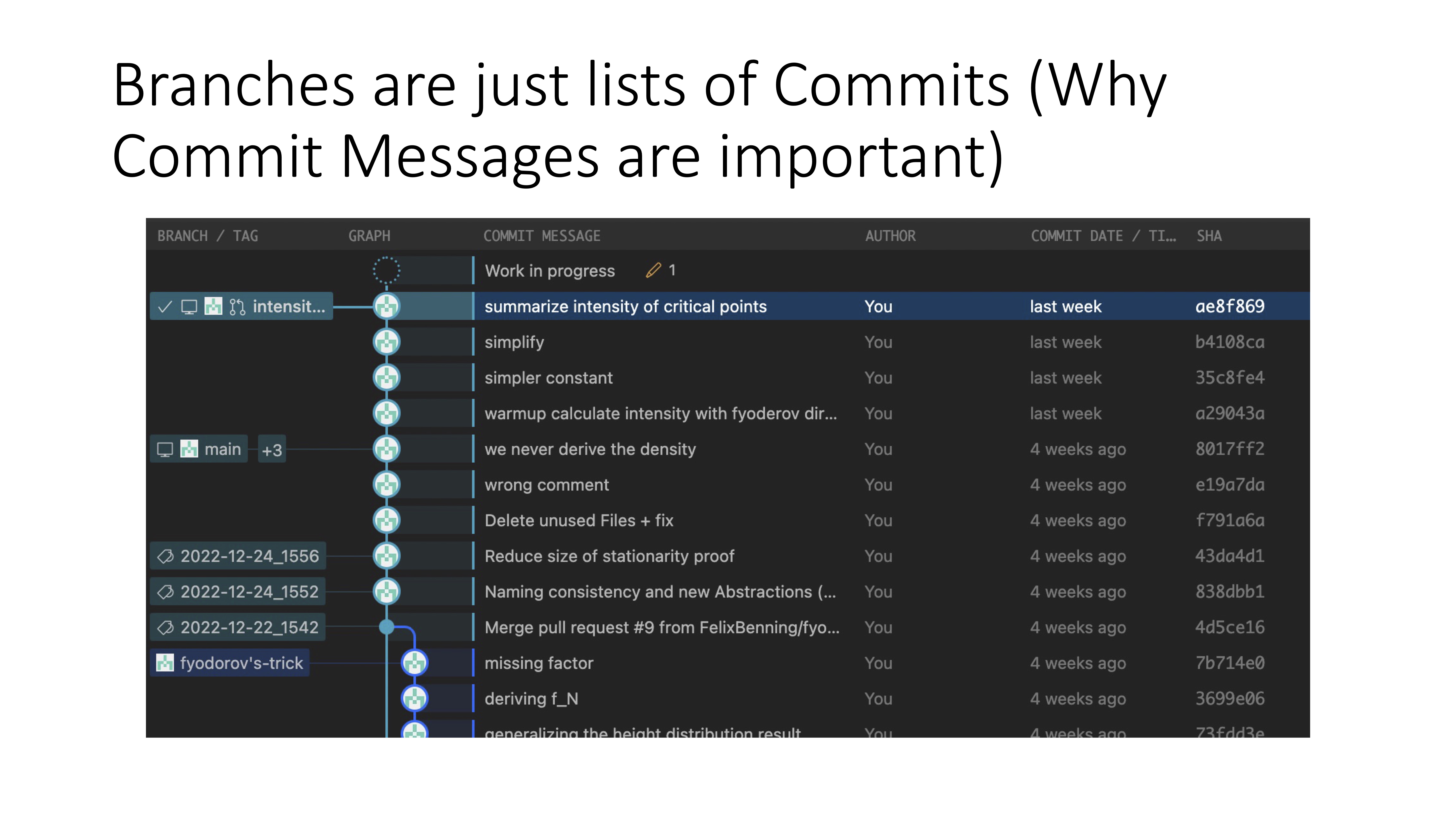
Branches on the other hand are simply lists of commits
, which represent
named version control checkpoints.
GUIs
Since a graphical user interface (GUI) is nicer than a command line, editors like Visual Studio Code provide an integration which executes those commands for you.

In particular it helps with merges, which are simultaneously the most useful and the most annoying part of Git
